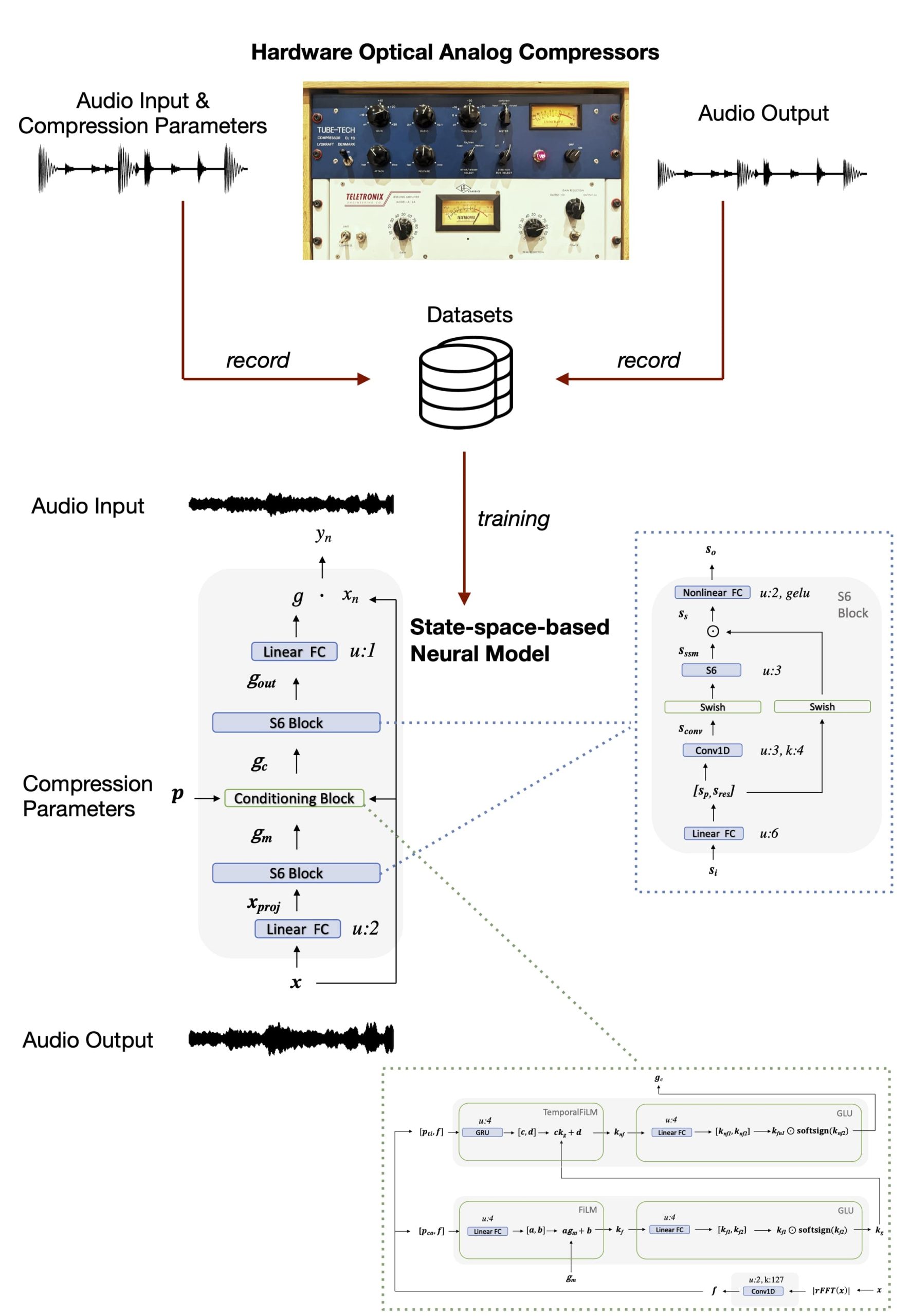
This work presents a method for modeling optical dynamic range compressors using deep neural networks combined with selective state space models. The approach surpasses previous methods that relied on recurrent layers by employing a selective state space block to encode the input audio. It features a refined technique that integrates feature-wise linear modulation and gated linear units, allowing the network to adjust dynamically and condition the compression’s attack and release phases according to external parameters.
The architecture is well-suited for low-latency and real-time applications, which are crucial for live audio processing. The method has been validated on the analog optical compressors Tube-Tech CL 1B and Teletronix LA-2A, each possessing distinct characteristics. Evaluation was performed using quantitative metrics and subjective listening tests, comparing the proposed method against state-of-the-art models.
Results indicate that the black-box modeling methods employed here outperform all others, achieving accurate emulation of the compression process in both seen and unseen settings during training. Additionally, there is a correlation between this accuracy and the sampling density of the control parameters in the dataset. The settings with fast attack and slow release were identified as the most challenging to emulate.
Source Code
Dataset
Audio Examples
Related Publication
R. Simionato, S. Fasciani, Modeling Time-Variant Responses of Optical Compressors With Selective State Space Models, in Journal of The Audio Engineering Society 73(3), 2025 [HTML]