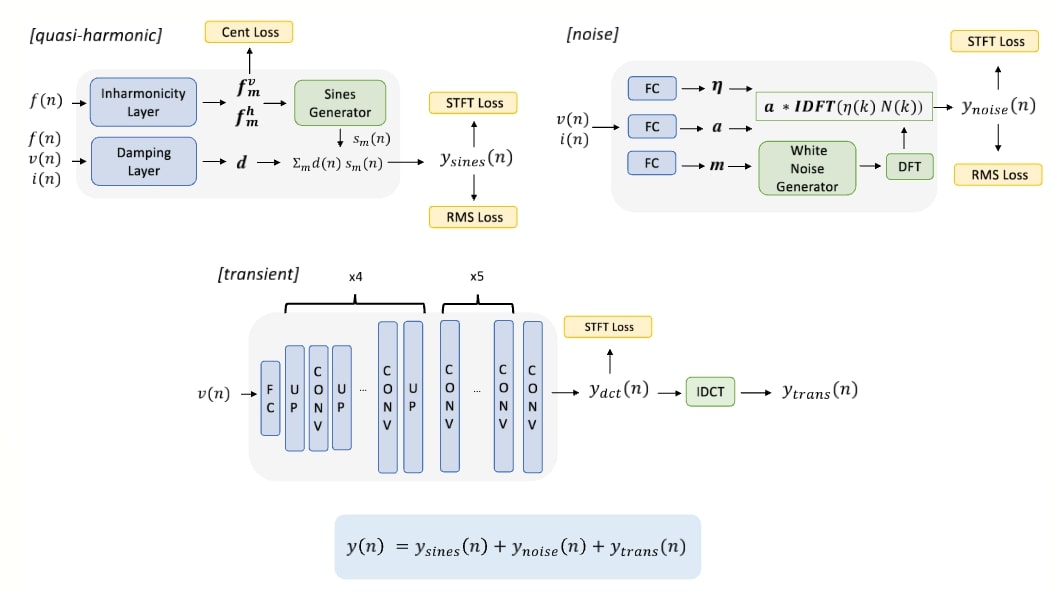
 This work introduces a novel method for emulating piano sounds, utilizing sine, transient, and noise decomposition to create a differentiable spectral modeling synthesizer that replicates piano notes. The method comprises three sub-modules that learn these components from piano recordings, generating the corresponding quasi-harmonic, transient, and noise signals. By splitting the emulation into three independently trainable models, we reduce the complexity of the modeling tasks.
This work introduces a novel method for emulating piano sounds, utilizing sine, transient, and noise decomposition to create a differentiable spectral modeling synthesizer that replicates piano notes. The method comprises three sub-modules that learn these components from piano recordings, generating the corresponding quasi-harmonic, transient, and noise signals. By splitting the emulation into three independently trainable models, we reduce the complexity of the modeling tasks.
The quasi-harmonic content is produced using a differentiable sinusoidal model, guided by formulas derived from physics; its parameters are automatically estimated from audio recordings. The noise sub-module employs a learnable time-varying filter, while the transients are generated through a deep convolutional network. To simulate the coupling between different keys in trichords, a convolutional-based network is utilized based on single note emulations.
While the model successfully matches the partial distribution of the target, it encounters greater challenges in predicting energy in the higher part of the spectrum. Overall, the energy distribution in the spectra of the transient and noise components is accurate. While the model is more computationally and memory efficient, perceptual tests indicate limitations in accurately modeling the attack phase of notes. Despite this, it generally achieves perceptual accuracy in emulating single notes and trichords.
Source Code
Dataset
Audio Examples
Related Publication
R. Simionato, S. Fasciani, Sines, transient, noise neural modeling of piano notes, in Frontiers in Signal Processing 4, 2025 [HTML]