This page includes of audio examples for the paper Simionato R., Fasciani S., Fully Conditioned and Low-latency Black-box Modeling of Analog Compression, in Proceedings of the 26the Digital Audio Effects Conference (DAFx23), Copenhagen, Denmark, 2023.
This page includes of audio examples for the paper Simionato R., Fasciani S., Fully Conditioned and Low-latency Black-box Modeling of Analog Compression, in Proceedings of the 26the Digital Audio Effects Conference (DAFx23), Copenhagen, Denmark, 2023.
Associated code, dataset, and trained models are available on GitHub.
Examples are available for the following compressor models:
Each example includes the following:
- Input Audio Signal
- Target Output Audio Signal (true output recorded from the device)
- Predicted Output Audio Signal (generated by the inference of the trained model)
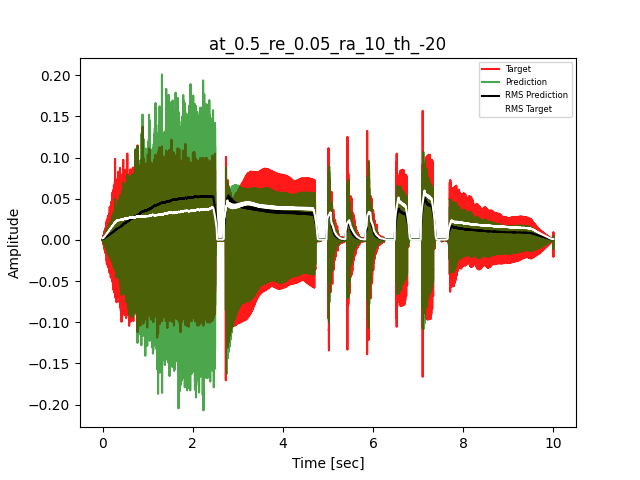
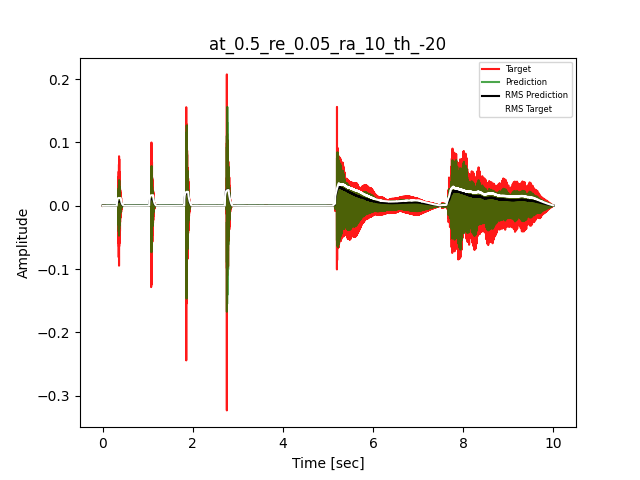
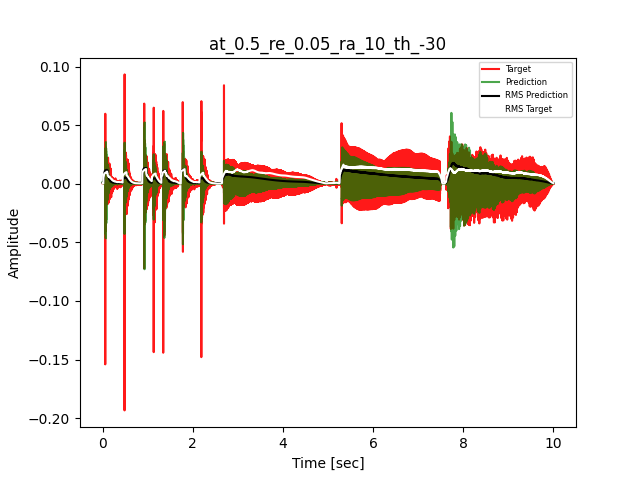
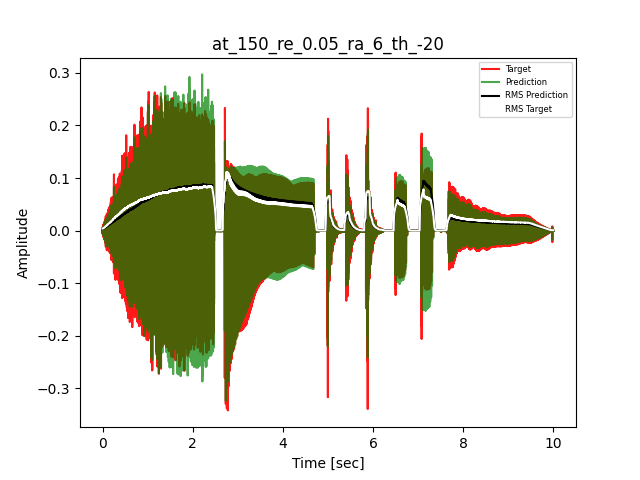
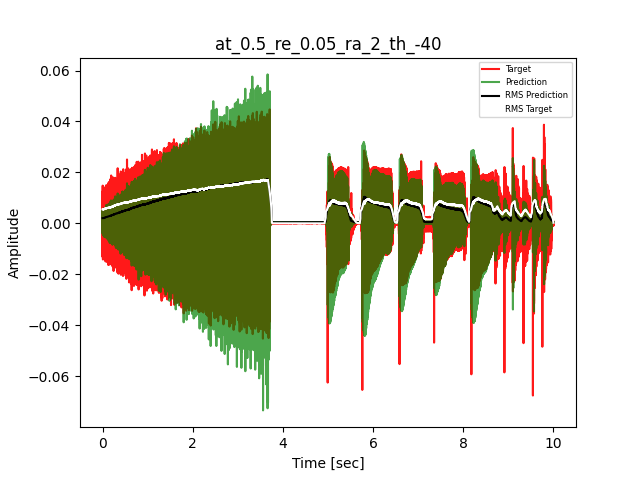
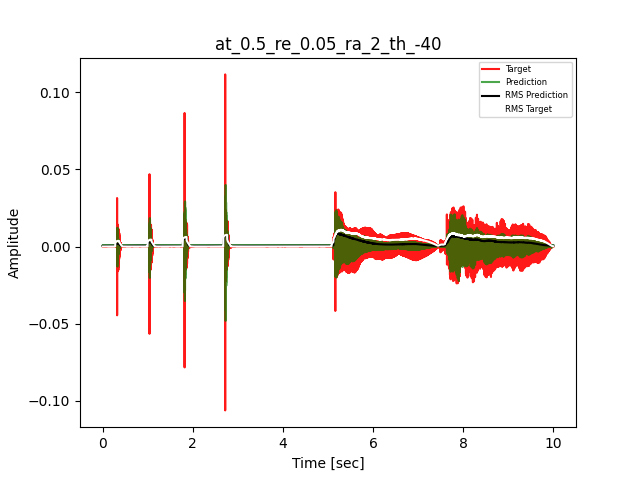
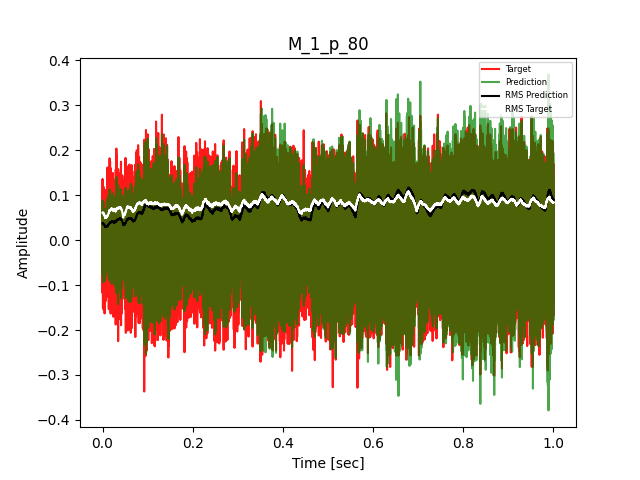
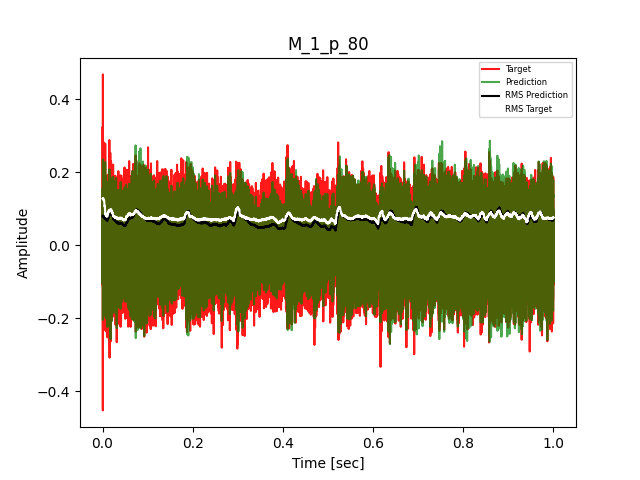
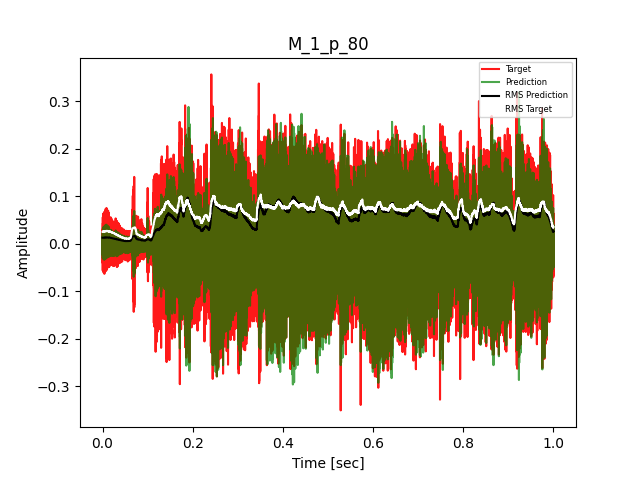
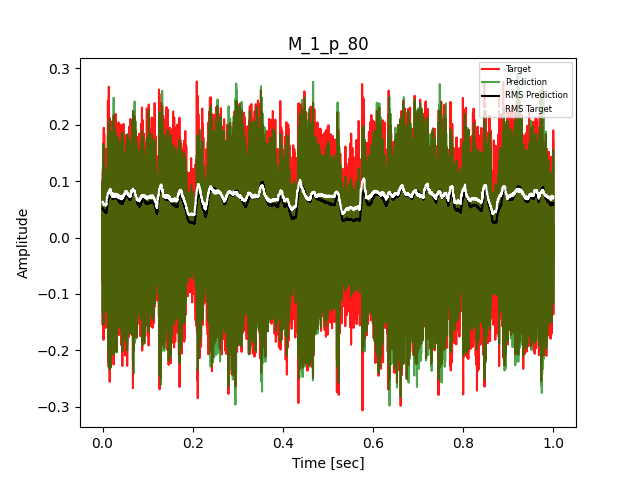
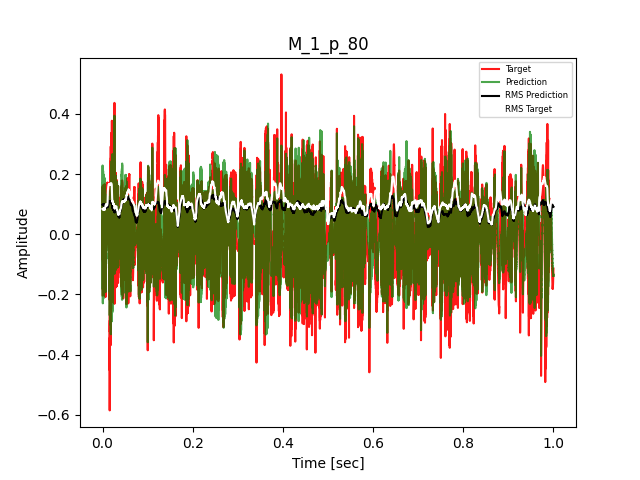
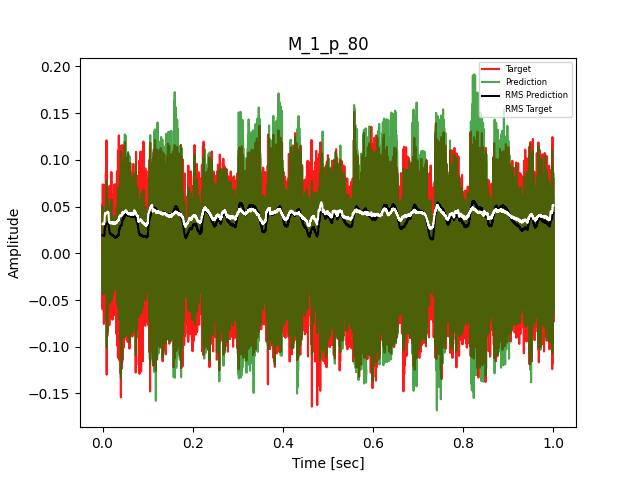
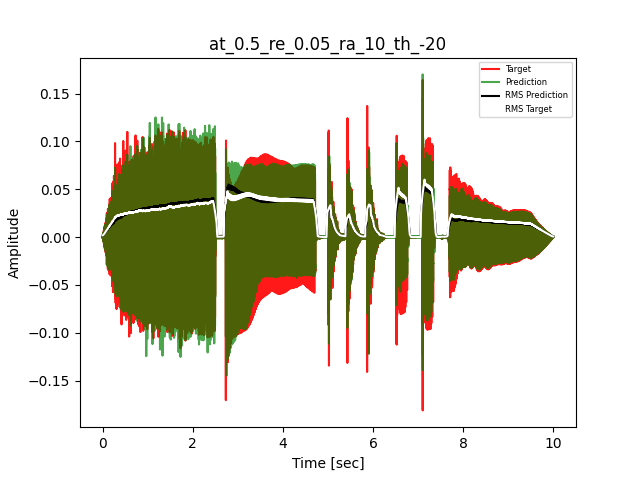
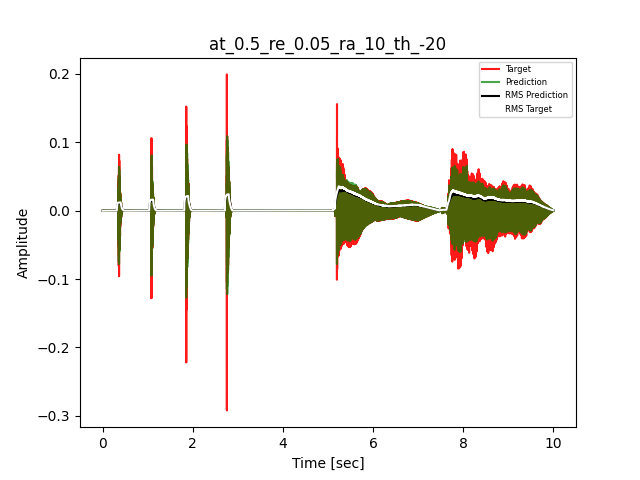
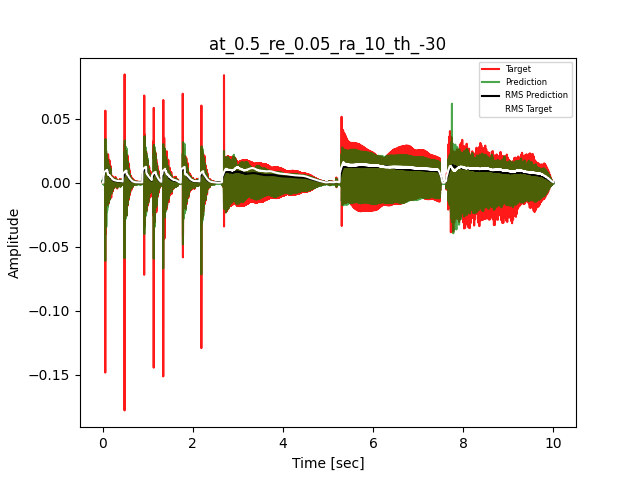
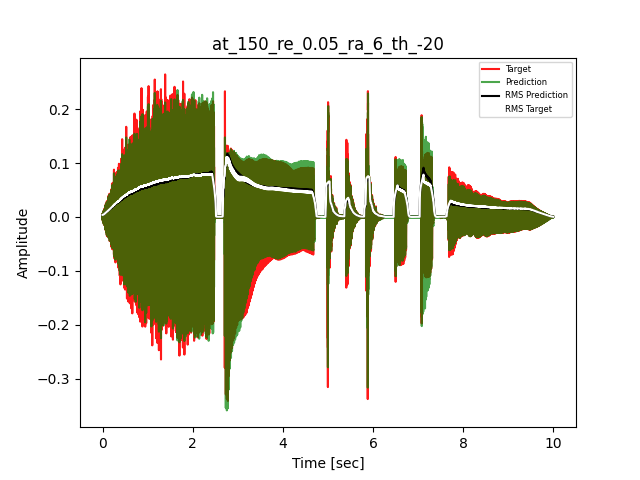
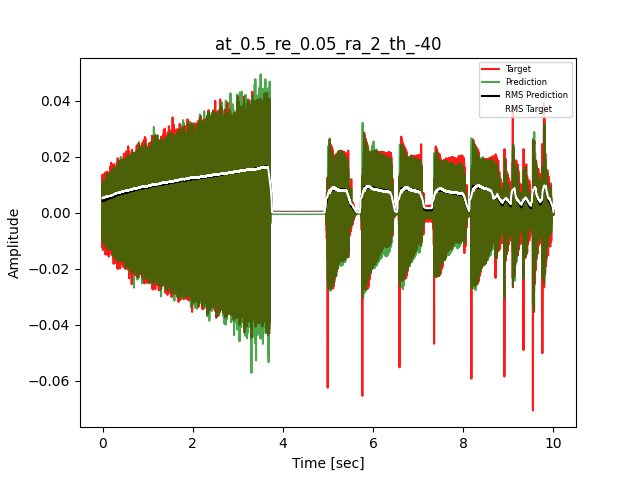
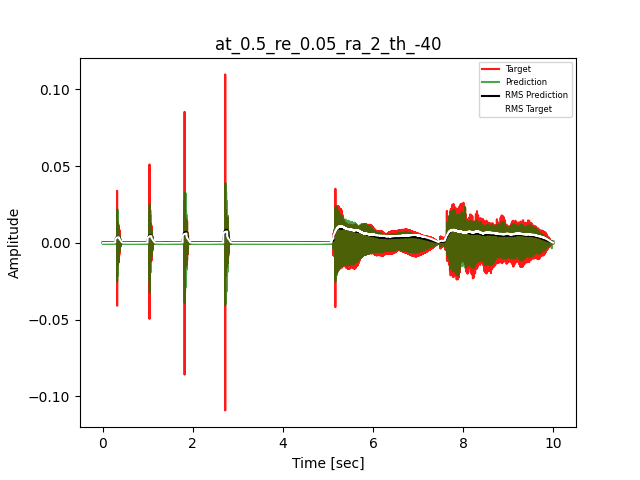
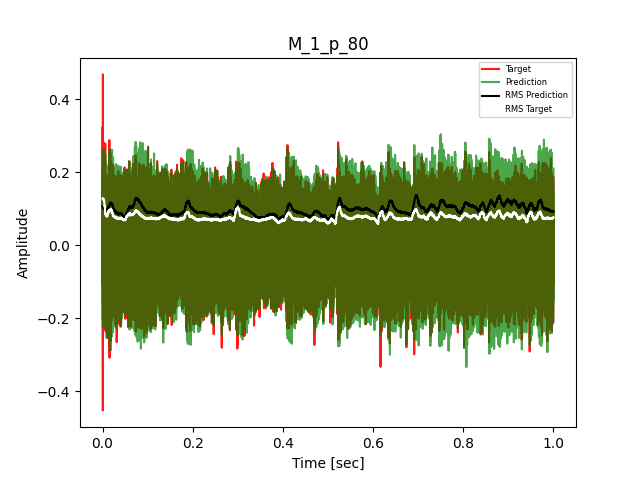
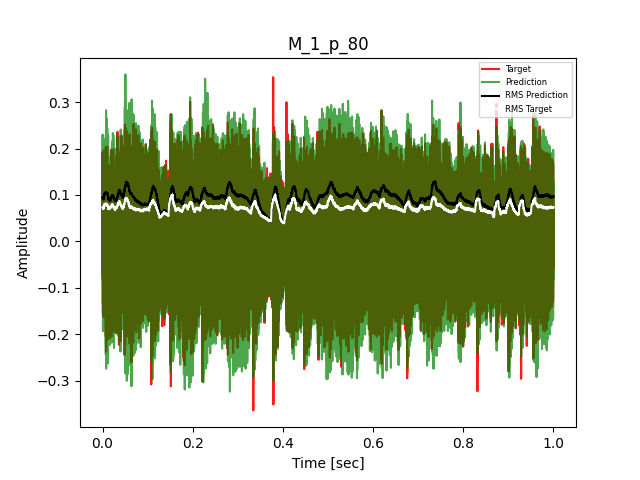
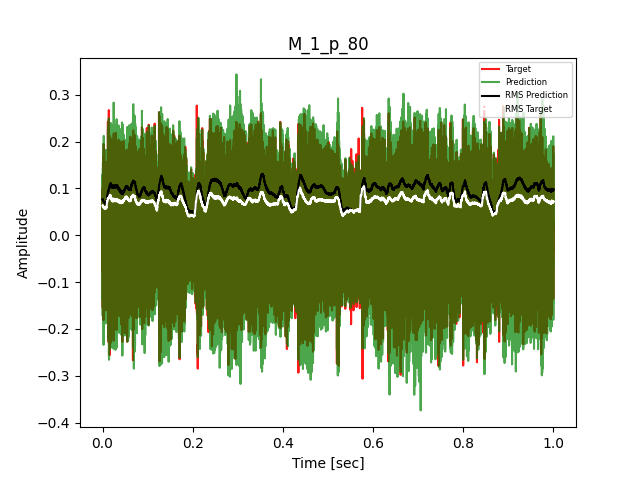
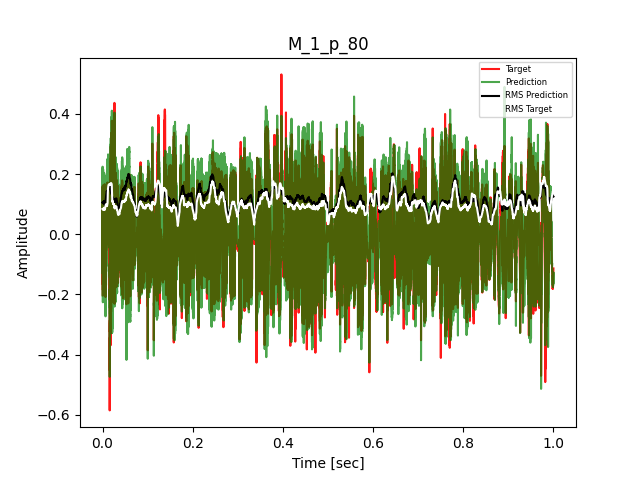
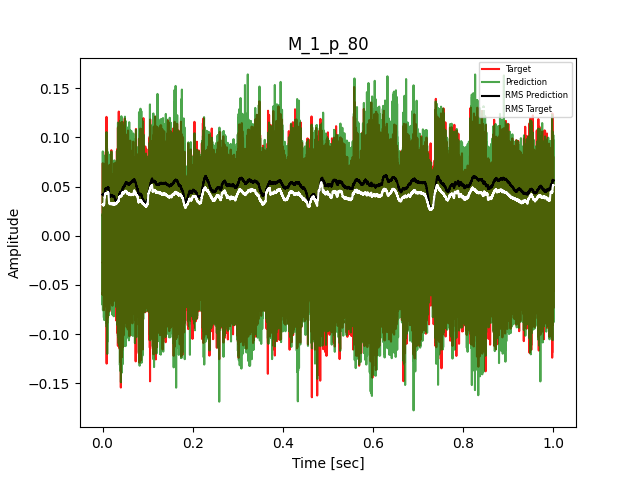
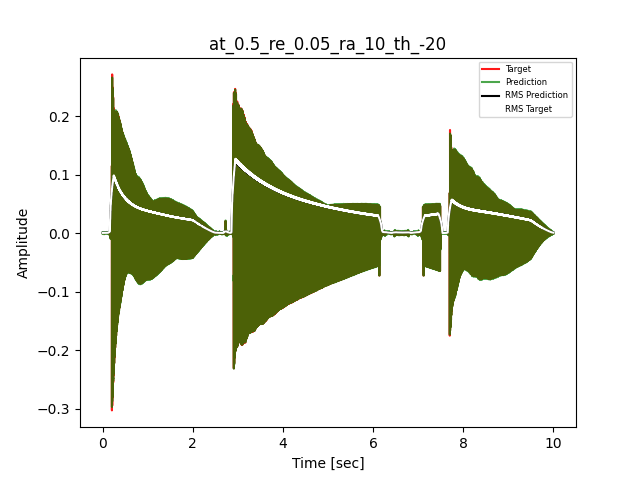
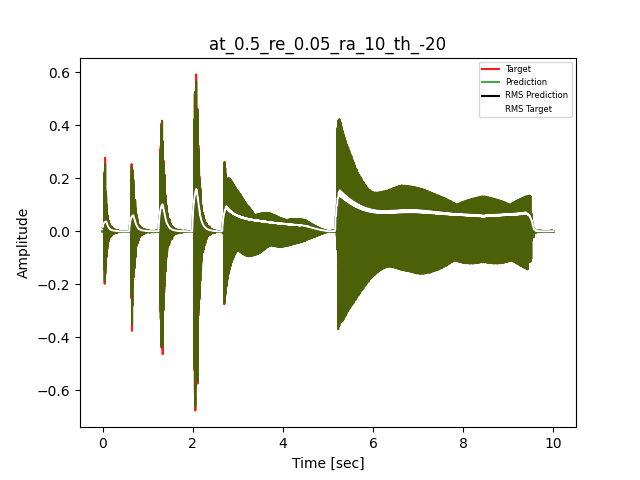
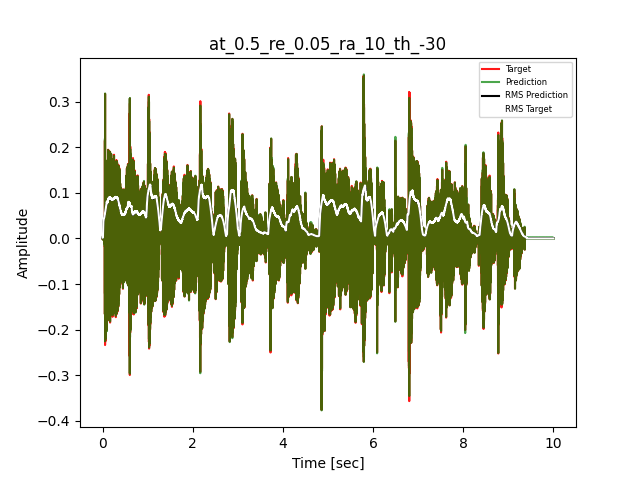
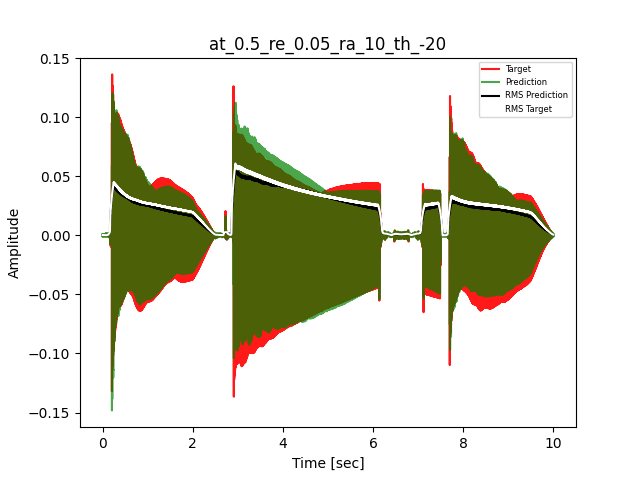
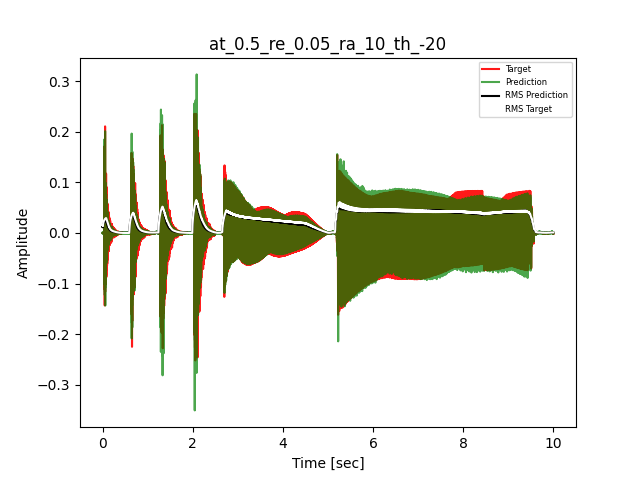
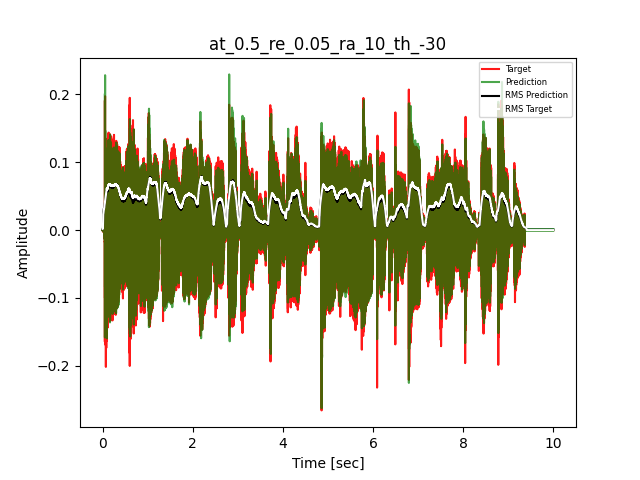
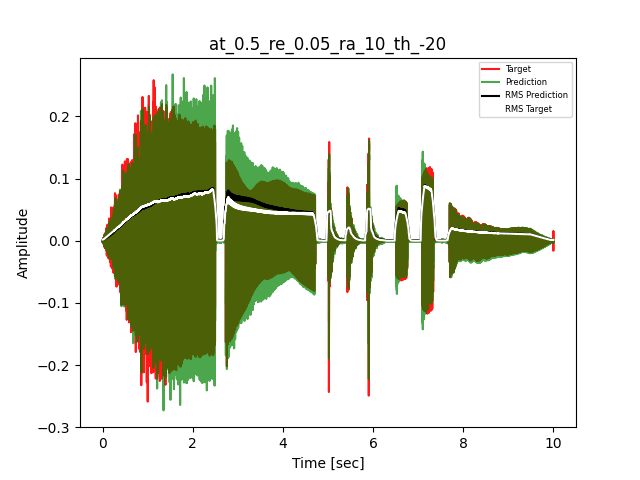
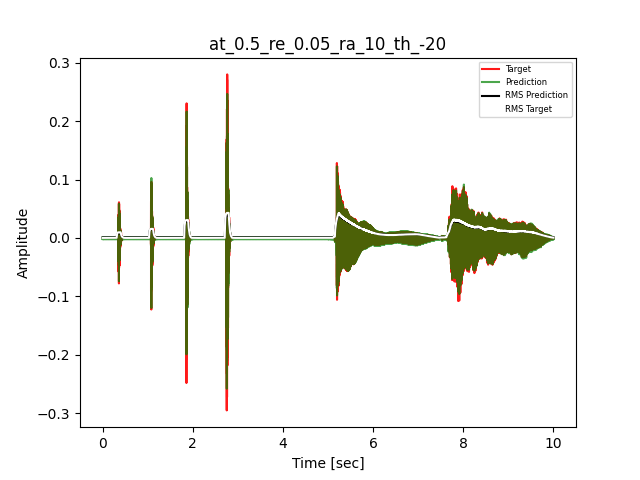
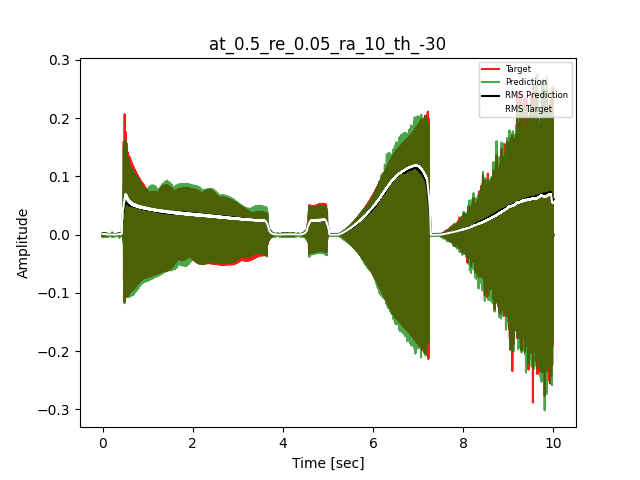
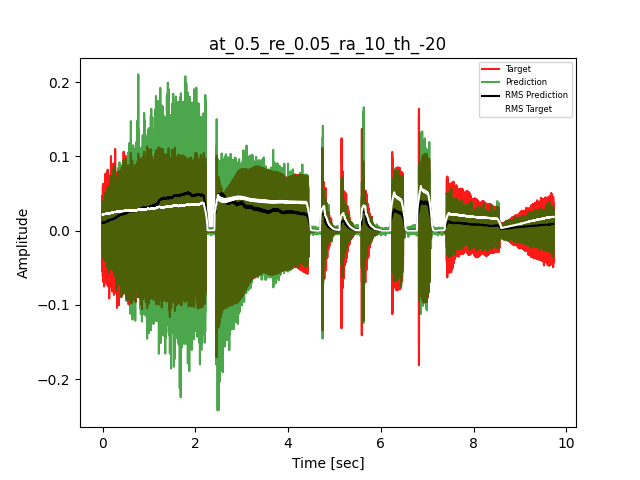
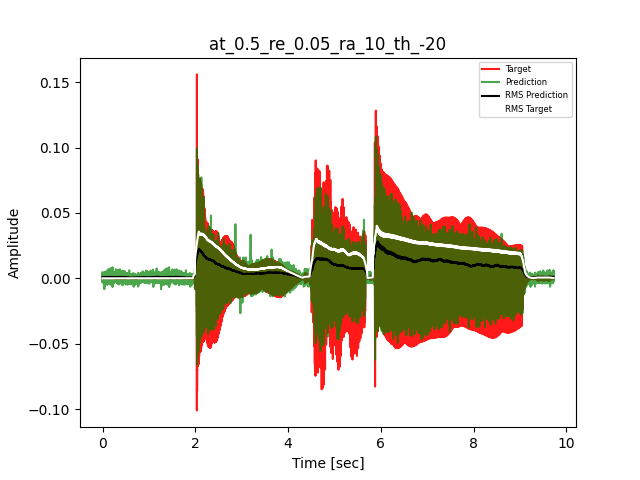
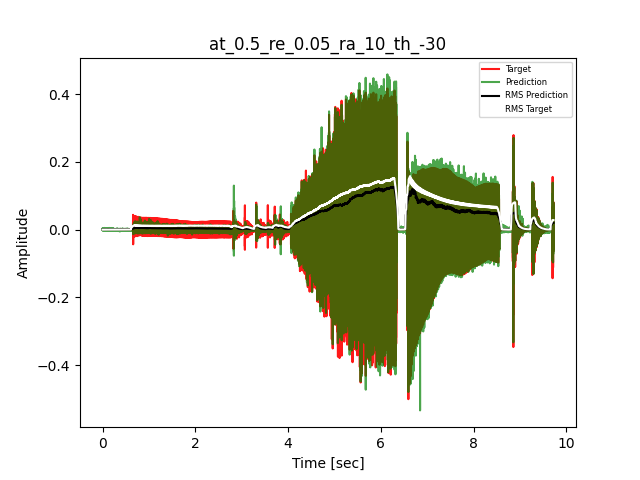
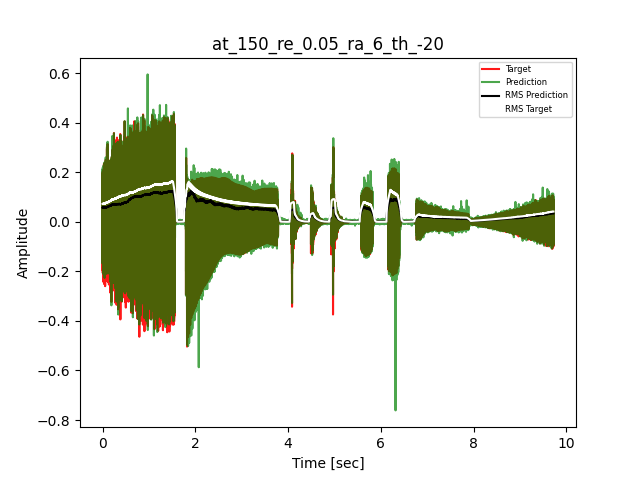
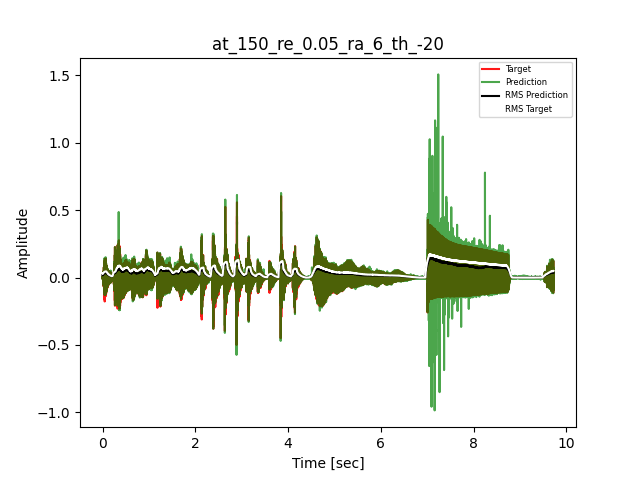
- Waveform of Target and Predicted Output Audio Signal with respective RMS values
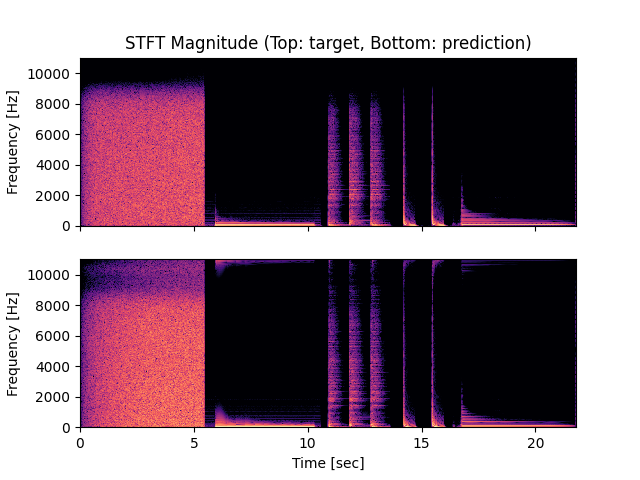
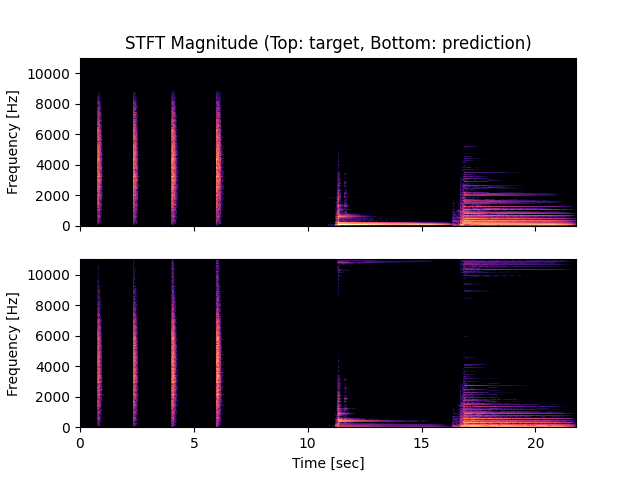
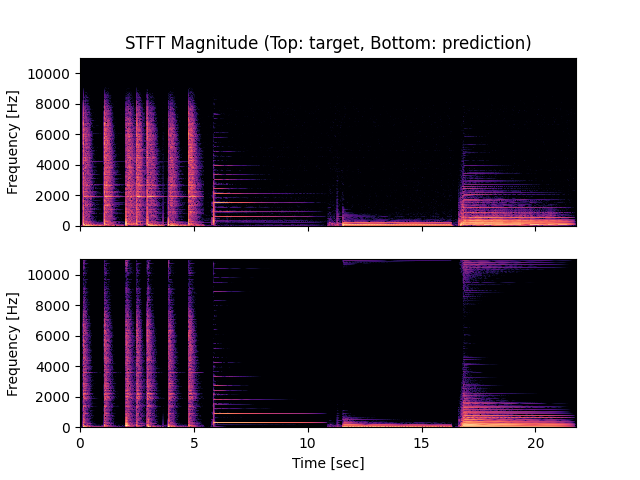
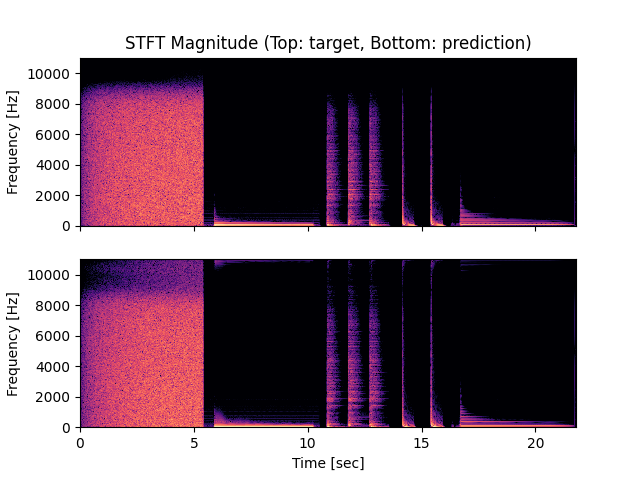
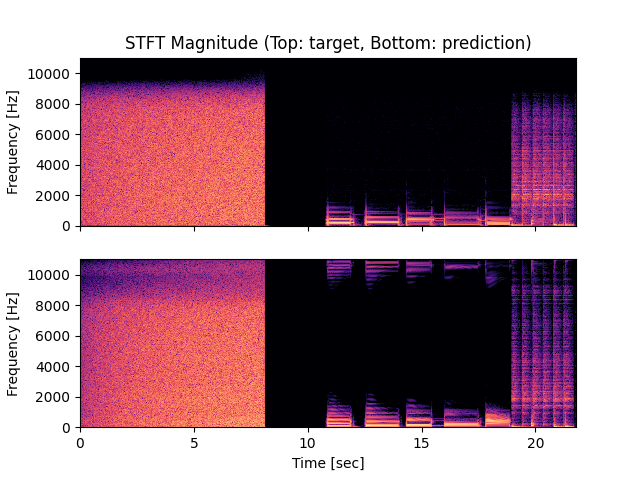
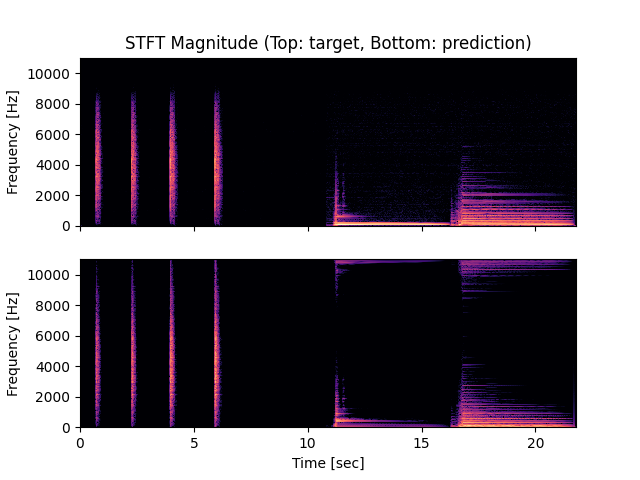
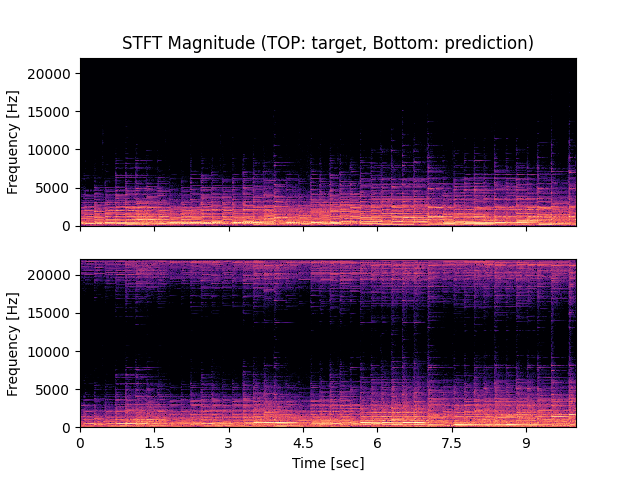
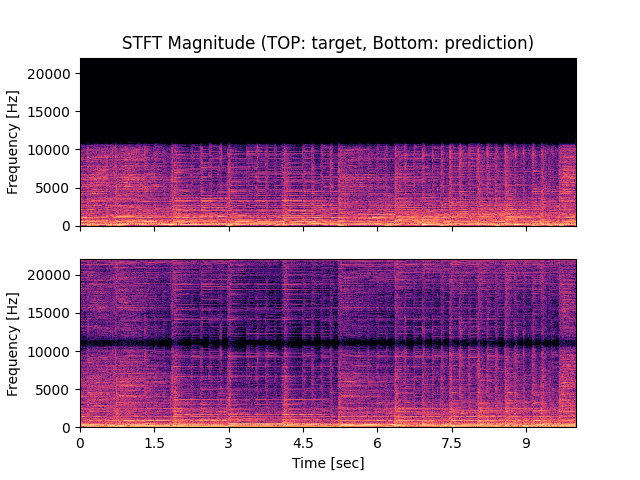
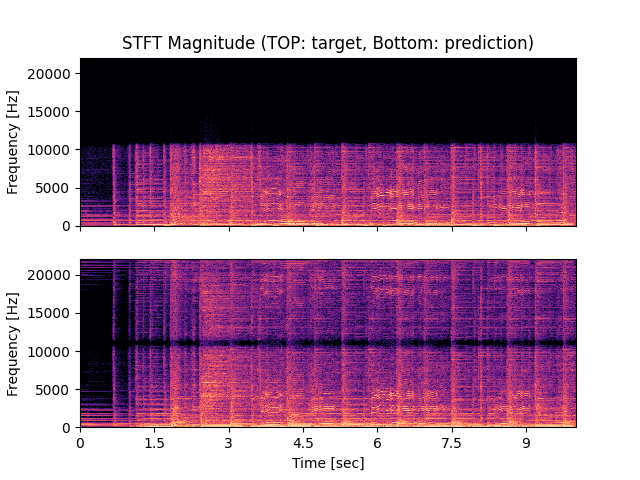
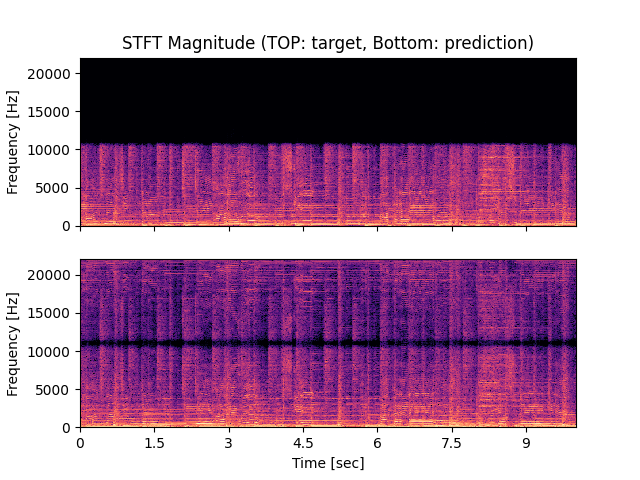
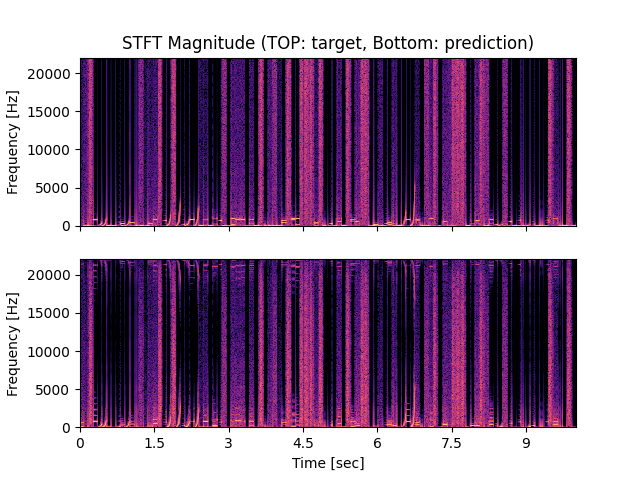
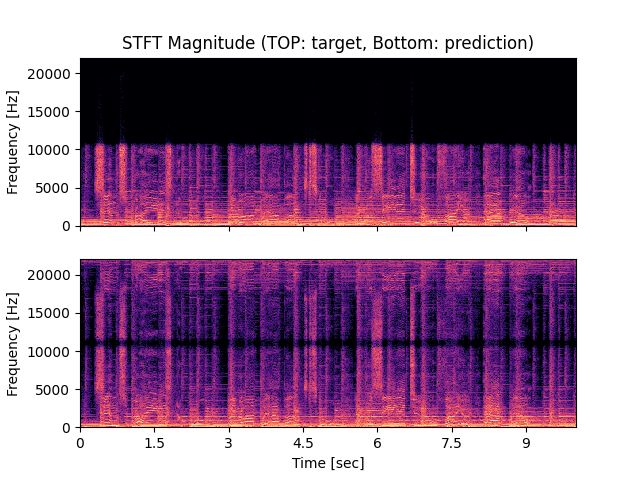
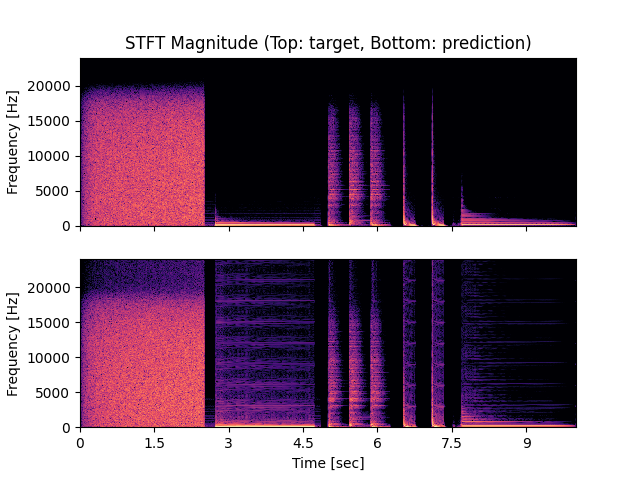
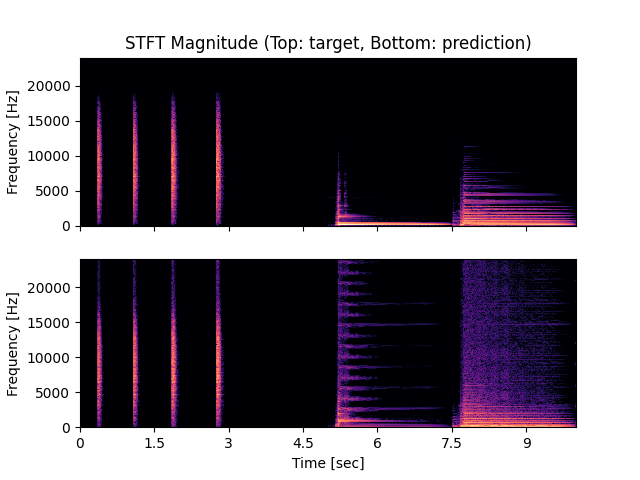
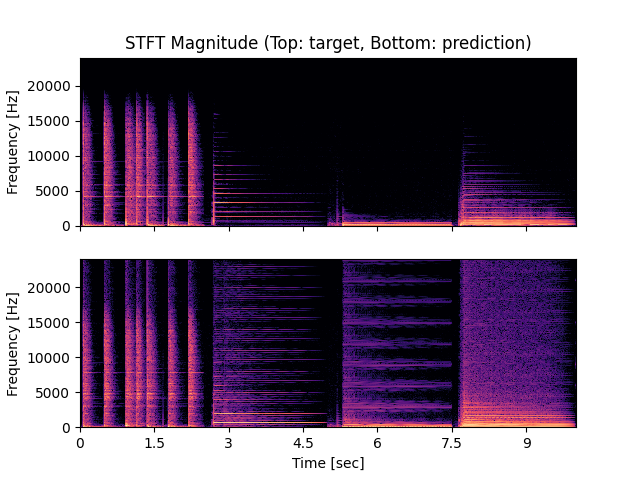
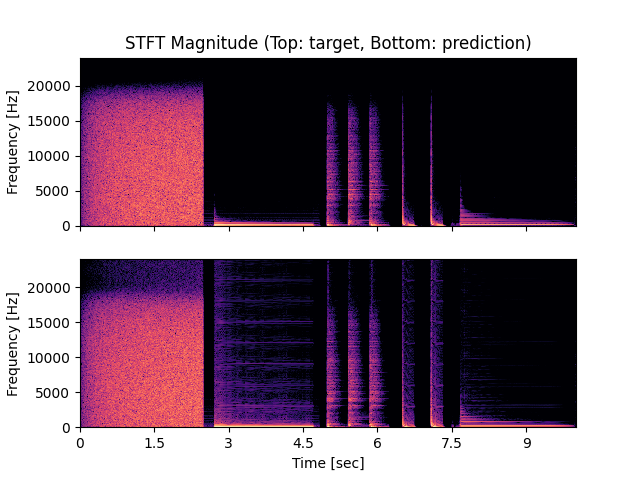
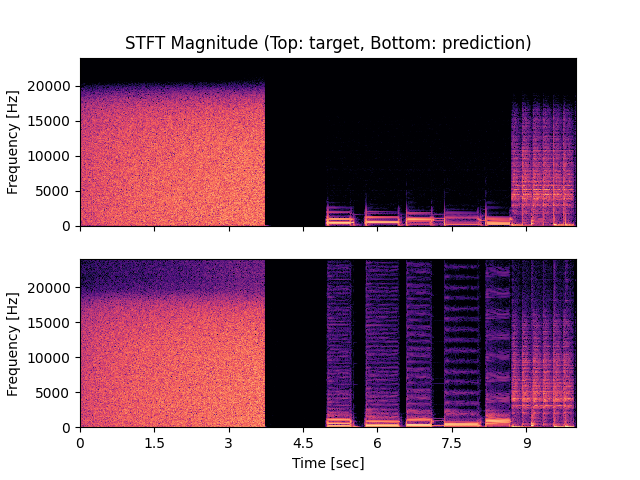
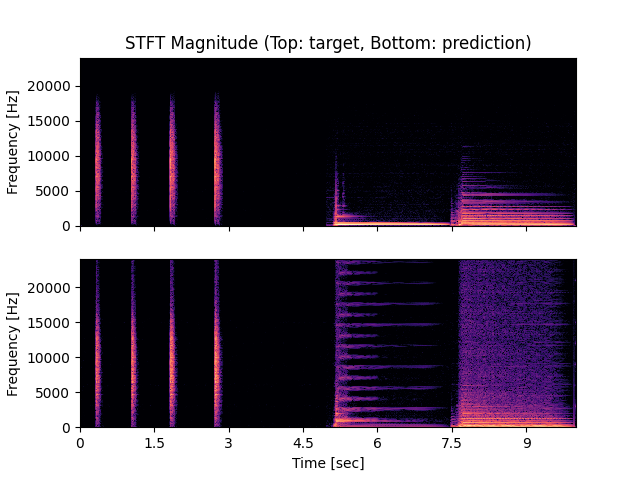
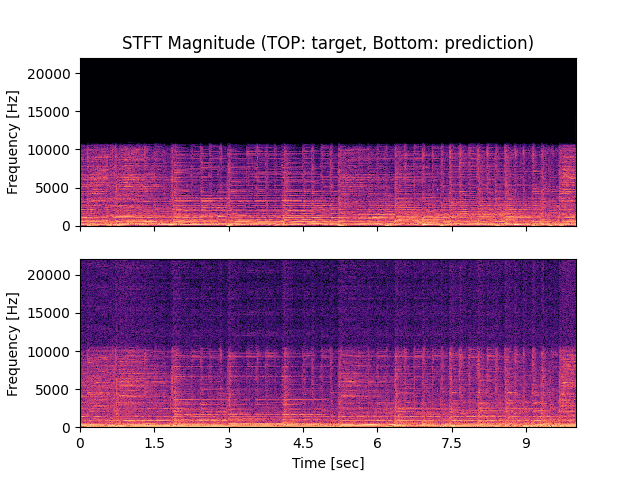
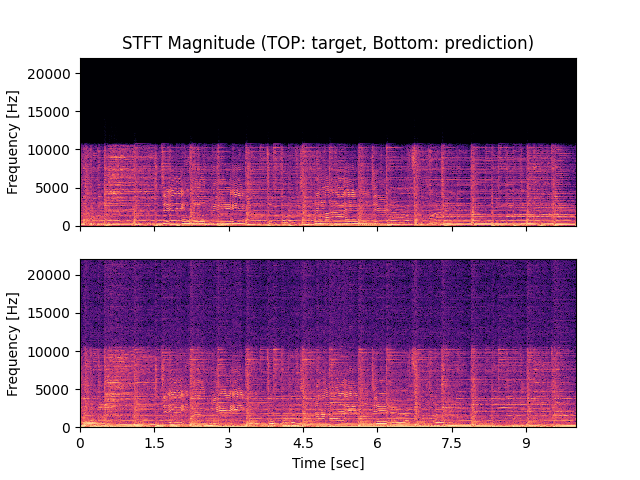
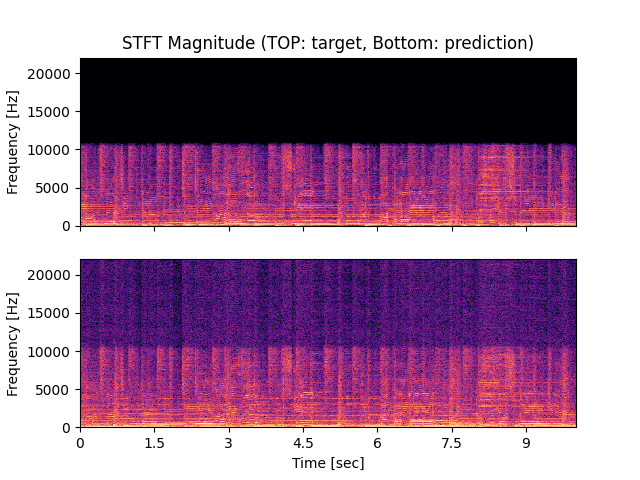
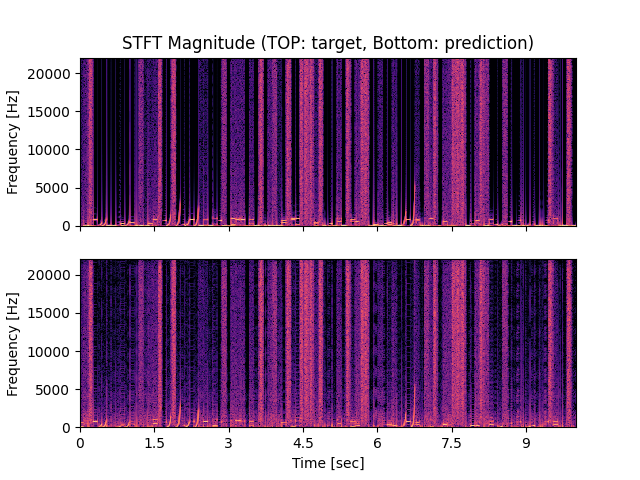
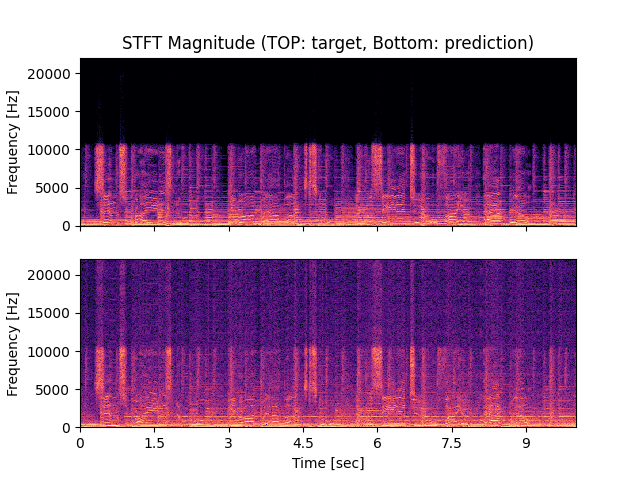
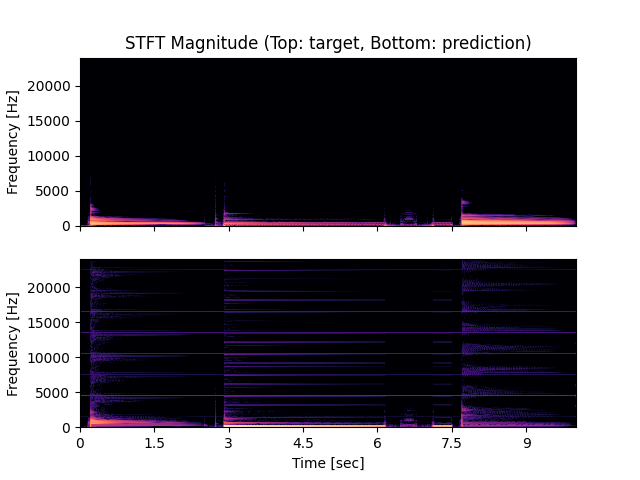
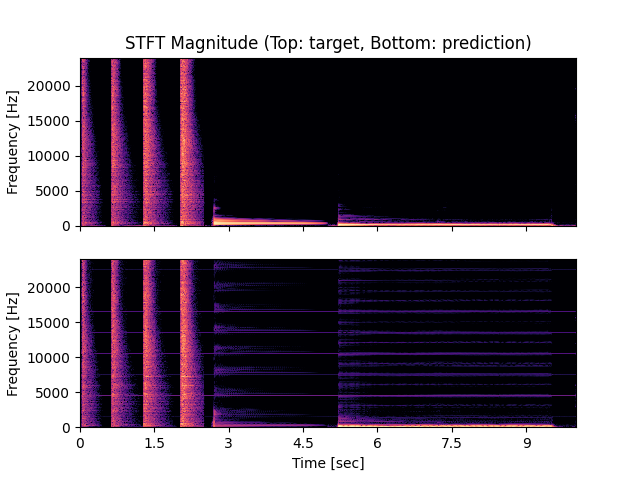
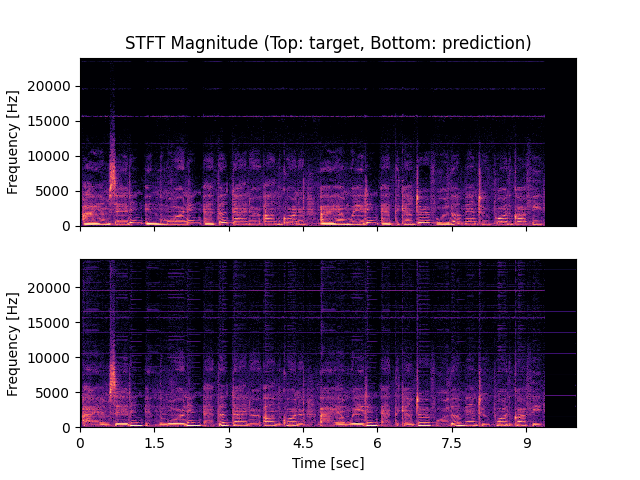
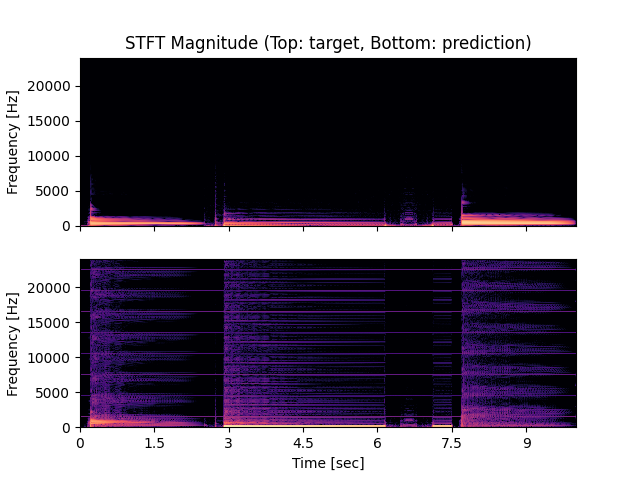
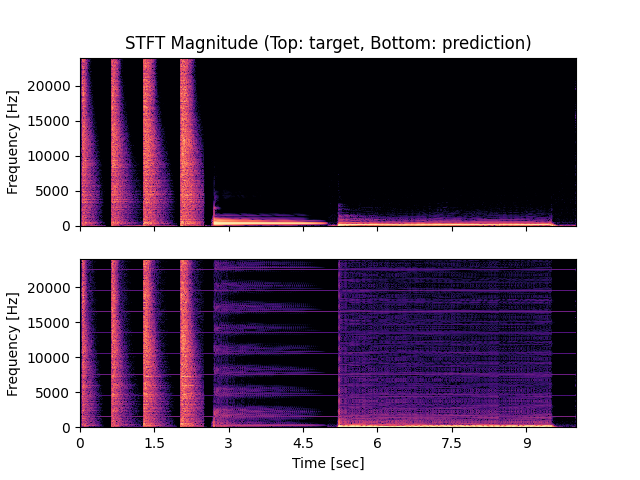
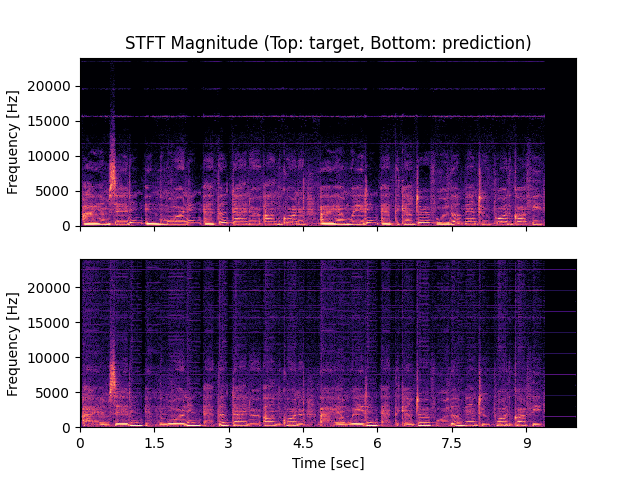
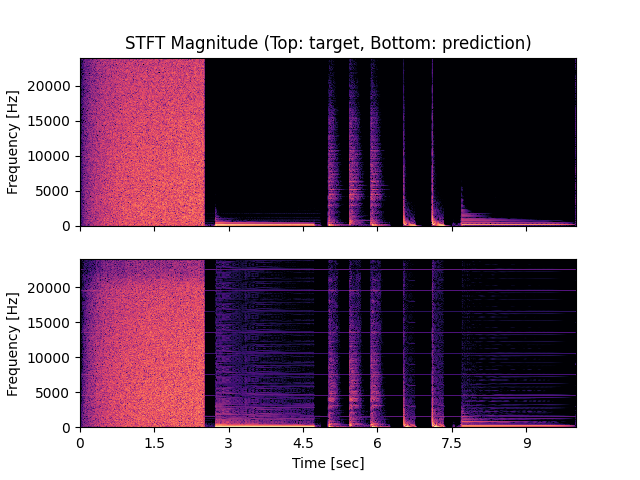
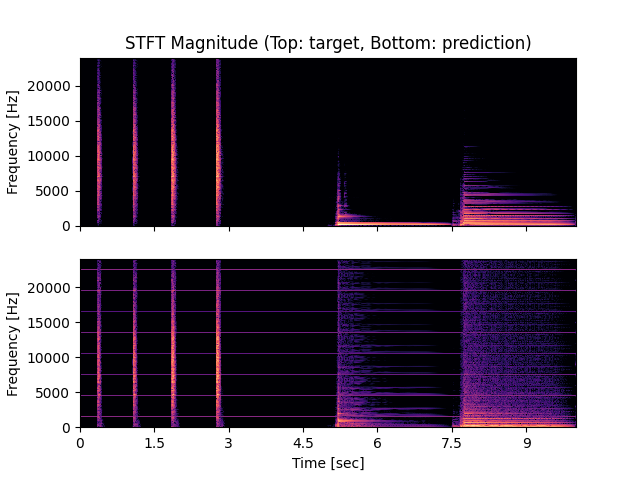
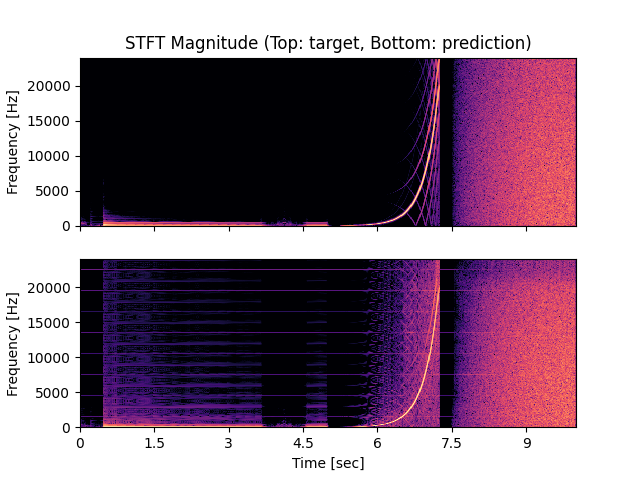
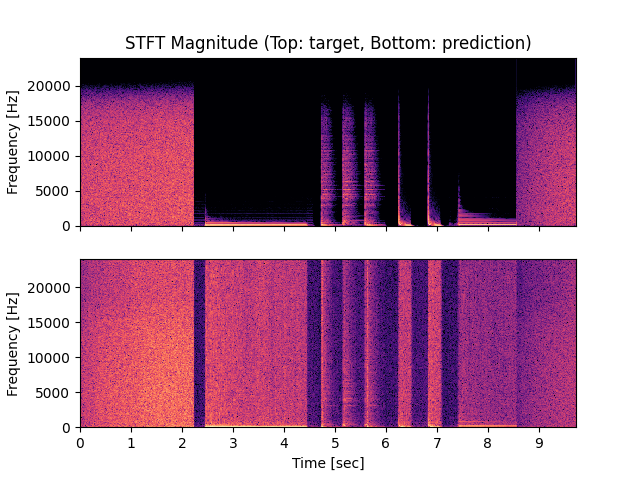
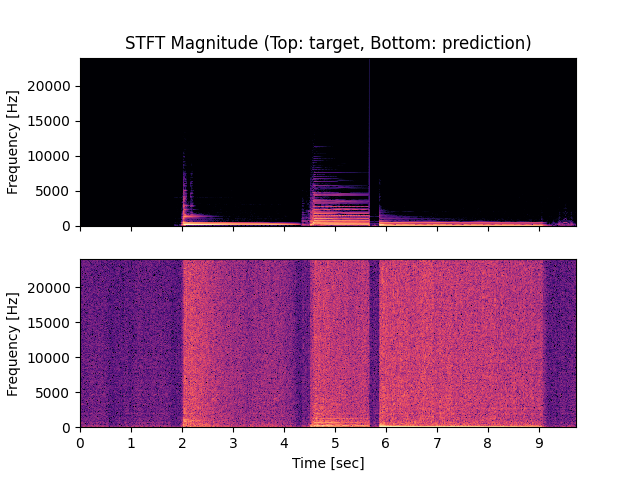
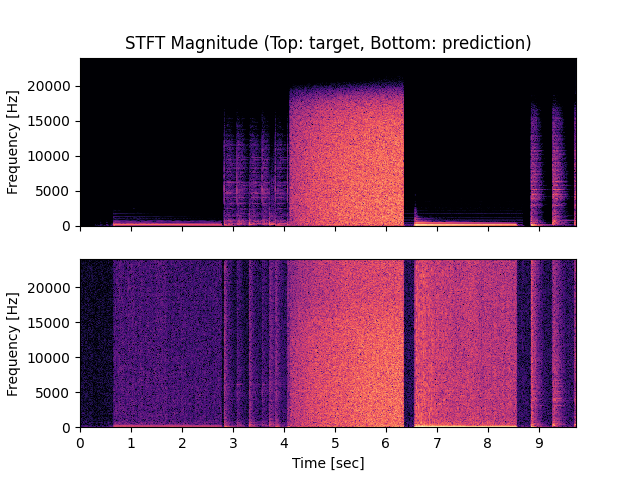
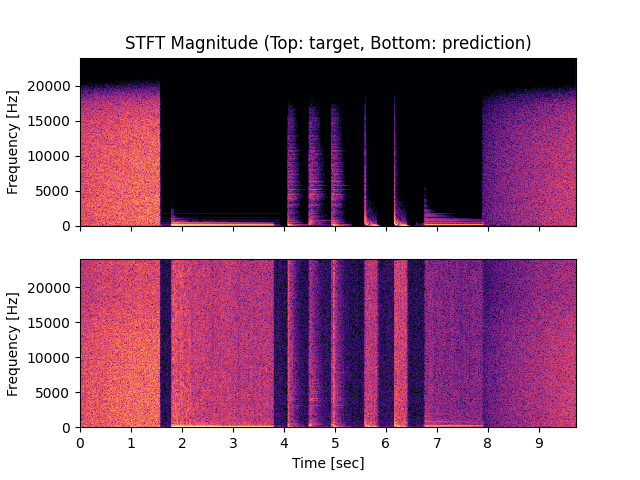
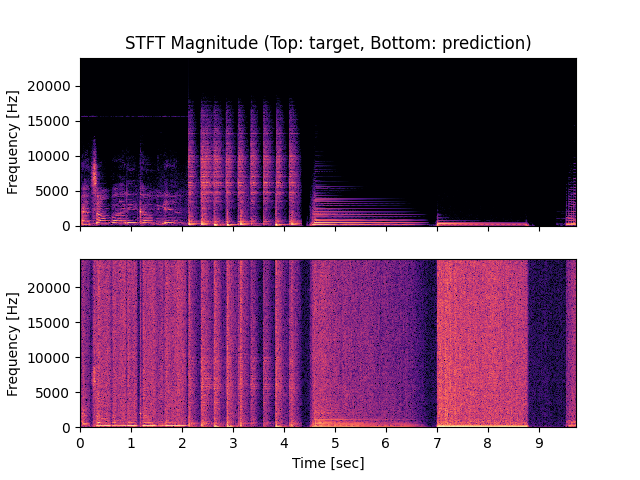
- Spectrograms of Target and Predicted Output Audio Signal
The title of the waveform plot details the compressor control parameters, valid for all devices except the LA-2A:
- at = attack time (ms)
- re = release time (s)
- ra = compression ratio (ra:1)
- th = threshold (dBu)
For the LA2A, the control parameters detailed in the title of the waveform plot are the following:
- M = mode (1 compression, 0 limit)
- p = peak reduction (dimensionless)
CL 1B Dataset – Encoder Decoder Light Model
Input
Target
Prediction

Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
LA-2A Dataset – Encoder Decoder Light Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
CL 1B Dataset – Encoder Decoder Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
LA-2A Dataset – Encoder Decoder Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
PSP MicroComp Dataset – Encoder Decoder Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
U-he Presswerk Dataset – Encoder Decoder Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Softube FET Dataset – Encoder Decoder Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
CL 1B Dataset – Temporal Convolutional Network Model
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
Input
Target
Prediction
 This page includes of audio examples for the paper Simionato R., Fasciani S., Fully Conditioned and Low-latency Black-box Modeling of Analog Compression, in Proceedings of the 26the Digital Audio Effects Conference (DAFx23), Copenhagen, Denmark, 2023.
This page includes of audio examples for the paper Simionato R., Fasciani S., Fully Conditioned and Low-latency Black-box Modeling of Analog Compression, in Proceedings of the 26the Digital Audio Effects Conference (DAFx23), Copenhagen, Denmark, 2023.